I have had the idea for a tool to automate, and optimise, threat modelling and related aspects of IT security for a while now. Over my many, many, years in IT security I’ve constantly been astonished how developers often couldn’t answer even quite simple questions about attack surfaces, and so the first several days of a gig would involve just trying to work out how a product works. In my certifications role, I was often tasked with explaining to some government how feature X worked, and why it was secure, and the often dire quality of documentation would regularly mean I’d have to go to the source code for answers. And I’ve lost count of the number of issues I’ve seen in programs and libraries written by SMEs and in the open-source world, that a simple and not-too-painful bit of targeted testing should have found.
A few months back, I resigned from my then employer, planning to take 6+ months off to work on my own projects, of which this is one. Around the same time I heard of the NCC Group’s Cyber10k. I decided to take a punt and enter my attack surface thingy idea, now called MINERVA, into the competition. I figured that if I won, then I’d have a few extra months to work on my projects before I had to get a real job. And irrespective, it would be good to get external validation of my ideas, and possibly also open up a pool of people who may be interested in alpha-testing.
Amazingly, I won!! And development is now proceeding at pace. The idea behind MINERVA has never been to make money from it (although that would be nice), but rather that I think there’s a real need for this tool. The status quo is shockingly poor, and my hope is that MINERVA will help the industry by automating something that is dull and slow to do, yet really useful. That said, what I’m trying to do is hard – I’ve estimated around a 75% chance of succeeding at all, and only 40% that it would meet it’s stated aims. This was recognised independently by the Cyber10k judges, and I’m extremely happy that they decided to take a punt anyway.
Following the Telegraph and NCC Group articles, I thought it would be useful to provide some more details on what MINERVA is, what problems it’s trying to fix, and overall what the design goals are. These have been extracted from my submission to the Cyber10k, albeit with assorted tweaks. When I submitted to the competition this whole product was purely theoretical, and there have unsurprisingly been design changes since then – no plan survives contact with the enemy – which I have noted below.
MINERVA Introduction
MINERVA is a proposed system which would address multiple issues found in today’s resource-constrained IT development environment. This represents the entry for the Cyber10k challenge “Practical cyber security in start-ups and other resource constrained environments”. It also partially addresses some aspects of other challenges.
The system makes the documentation of attack surfaces, and by extension threat models, easier to do by non-experts. It does this by simplified top-down tools, but primarily through the use of bottom-up tools which will attempt to automatically construct attack surface models based on the code written. Using these combination of tools, plus others, the system can correlate between high level design and low level implementation, and highlight areas these do not sync. It can also automatically detect and track changes in the attack surface over time.
By making the system scalable, MINERVA will allow integration of attack surface models from large numbers of components, allowing high level views of the attack surfaces of large systems up-to and including operating systems and mobile devices. Allowing cloud integration enables support even amongst third party and open source components, together with dynamic updating of threats when new vulnerabilities are identified.
This greater knowledge of attack surface can then be used to prompt developers with questions about threat mitigations, and help them consider security issues in development even without the input of security specialists, thus raising the bar for all software development which uses MINERVA. It can further be used by security specialists to identify areas for research, centrally archive the results of threat modelling and architecture reviews, and generally make more efficient use of their limited time.
Problem Definition
Threat modelling has been proven to be an excellent tool in increasing the security of software. It is built into many methodologies, most notably the Microsoft Security Development Lifecycle. A well written threat model, with good coverage, attention made to mitigations, and then with testing of those mitigations, will likely help lead to a relatively secure product – certainly above industry standards.
Unfortunately threat modelling is difficult, and generally requires security specialist involvement, and there is always a shortage of specialists with the correct skills. There have been numerous attempts to make the process simpler to allow developer involvement, and to educate developers, but these have had minimal impact in general – unfortunately developers are also regularly in short supply, are over worked, and so are unwilling to sink time into a process with, to their mind, nebulous benefits.
Indeed, it’s not uncommon for developers to barely document their work at all, let alone create security documentation. As developers move away from traditional waterfall design and development to newer methodologies such as AGILE, this problem is only getting worse, and even if written at some point, they rapidly fall out of date. Even under waterfall methodologies, where design documents exist, it is common for implementation itself to be quite different, and it’s rare for developers to go back and update the design documents. Even when threat modelling is performed, these are often stored in a variety of formats such as Word documents, as well as threat-modelling specific formats such as the Microsoft .tm4 files. These are rarely centrally stored and archived, and so it can be difficult to identify whether a threat model has been created, let alone how well it was written, and whether it was actually used for anything.
Furthermore, products are becoming more complex over time. Threat models are often written for a specific feature or component, but these are rarely linked with others. Assumptions made in one component, such as that another component is performing certain checks on incoming data, are not always verified leading to security vulnerabilities deep within a product. Even if the assumptions were correct initially, this does not mean the assumption will be correct several versions of software later.
Finally, open source and other third party components can lead to complications. These may be updated without the product developer being made aware, and this may be due to security issues. Developers rarely wish to spend time performing threat modelling and the like on code they do not own, and for non-open-source components it may not even be possible to do so due to a lack of product documentation.
Solution Objectives
MINERVA attempts to address the problems described above. Prior to the design itself, it is worthwhile to call out the high-level features the solution should have – what are the objectives of MINERVA.
Attack surface analysis
It must be possible for a user to create, view, and modify an attack surface model. This must include an interface which uses data flow diagrams (DFDs), and also via a text-based interface. Other diagrams such as UML activity diagrams may be supported.
Centralised storage
Attack surface models must be stored in a centralised location. This should be able to be used to provide a holistic view of an entire product. Change tracking must be supported, together with warnings when changes in one model impact assumptions made in another. Attack surface models must be viewable at different levels of granularity, from product/OS down to process or finer grained.
The centralised storage must support authentication and authorization checks. There must be administration, and audit logging.
It should be possible to perform an impact analysis of security issues found in third party bugs.
Distributed storage
It must be possible for different instances of MINERVA to refer to or pull attack surface models from each other, subject to permissions. For example, the attack surface model for a product which uses OpenSSL should be able to just refer to the attack surface model for OpenSSL, stored on a public server, rather than having to re-implement its own version.
This distributed storage must support dependency tracking and versioning, such that the correct versions of attack surface models are used, and also such that a warning can be provided if a security vulnerability is flagged in an external dependency.
External references should support both imports as well as references, allowing use by non-internet-connected instances of MINERVA. Generally the relationships between servers should be pull, rather than push.
Automated input
It must be possible for automated tools to import and modify attack surface models, or parts thereof. These tools should include the scanning of source code, binaries, and before/after scans of systems when a product is installed or run.
The protocol and API for these must be publicly documented and available, to allow third parties to extend the functionality of MINERVA.
Manual Modification and Input
It must be possible for users to manually create, edit, and view attack surface models. Different interfaces may be desired for developers, security specialists, and third party contractors. Threat models must also be editable.
Automated Analysis
It must be possible for automated tools to analyse stored attack surface models. The protocol and APIs for this must be publicly documented.
There must be a tool which takes an attack surface model, and generates a threat model, which a user can then modify. A tool should be able to generate test plans.
Tools must exist which detect changes in the implementation or design, and which identify where the design and implementation of a product differ.
A tool could be provided which would allow the application of design templates, for example Common Criteria Protection Profiles, which would be used to prompt the creation of an attack surface model, and allow exportation of parts of a Common Criteria Security Target.
Workflow fits in with standard methodologies
Where possible, use of MINERVA should fit in with standard development methodologies. For top down waterfall methodologies, the diagrams created within MINERVA should be the same as those used in design documentation – it should be possible to trivially import and export between MINERVA and design documentation. For Agile, this should mean dynamic creation of models based on source code, change tracking, and generation of test plans and the like.
Due to the plethora of design methodologies, this objective can be met if it will be feasible to write tools which provide the appropriate support, and some sample tools may be written for a subset of common methodologies – one top down, and one iterative/Agile – as proofs of concept.
Solution Design
High level design
Architecture
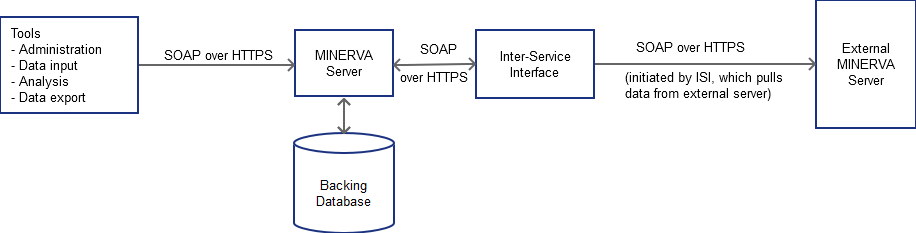
The high level architecture for MINERVA is extremely simple, as shown in Figure 1. A database holds the attack surface models, threat models, and administrative details such as usernames and passwords. Access to the database is mediated by the MINERVA server itself. The server also performs validation of attack surfaces, authentication and authorization, and interpolation between attack surface levels – for example if a tool requests a high level simplified attack surface model, but the server only has a very low level detailed model, then the server will construct the high level model.
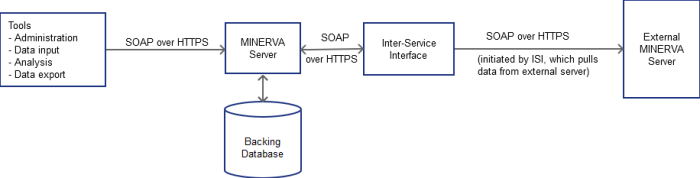
Figure 1: High Level Architecture
All tools (including the Inter-Service Interface) communicate with the server via the same SOAP over HTTPS interface (Note: Currently using json over HTTPS). An exception may be made for administration, restricting access to only a single port – thus allowing firewalls to restrict access to only an administration host or network. Authentication will initially be against credentials held in the database, however the aim is to allow HTTP(S) authentication, and thus allow Kerberos integration and the like.
The ISI will be used to pull data from remote instances of the MINERVA server. This will use the same protocol and authentication as other tools – it is essentially just another tool connecting to the external server.
Attack Surface Models
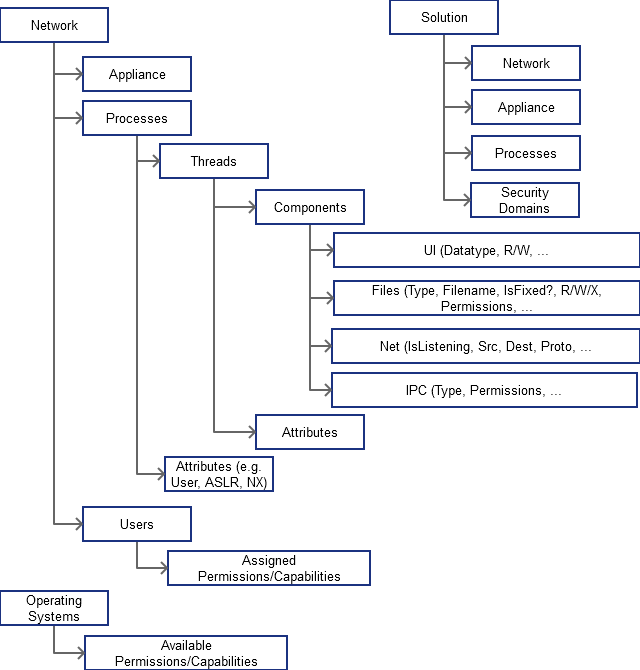
The main data stored within the database is the attack surface models. Figure 2 shows the structure of an attack surface model. The database schema will be based around this.
Under the preliminary model of an attack surface model, a solution is made up of a set of networks, appliances (which are situated on networks, and processes (within the appliances), and security domains. A network in this context is a logical group of components, which may or may not be on the same local network. An appliance is the hardware and operating system, although there will initially be an assumption that there is only one operating system on a set of hardware – i.e. virtualisation will initially not be supported. A process relates to an operating system process. In general, a security domain will align with a network, appliance, and/or process. Generally a security domain boundary can be present between processes, and/or between processes/components and assets.
Any time a dataflow crosses a security domain boundary, there is the opportunity to place a filter on either side of the boundary – for example for a network protocol dataflow, this could be a firewall, and for IPC it could be permissions.
A network is made up of Appliances, which contain processes. The network as a whole is deemed to have a set of users – these are abstract users used to differentiate between users with different permissions and capabilities, and in different security domains.
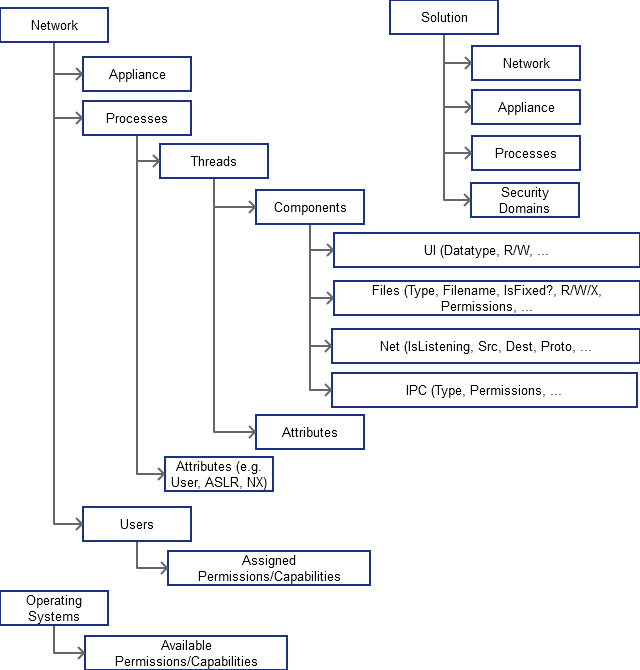
Figure 2: Attack Surface Model
Appliances contain operating systems – these are used to define the allowable set of permissions, capabilities, and the like that a user or process may be given.
Processes have attributes, and are made up of threads. Threads have attributes and are made up of components. Components interact with each other, and with assets and dataflows such as files, IPC, network connections, and user interface. (Note: Currently I’m collapsing all threads in a process into a single thread – this is for simplicity sake).
Generally high level attack surface models are made up of networks, appliances, and optionally processes. Low level models are made up of components, threads, and processes. Of course, at each level there may be abstractions such as grouping several processes or appliances together. This structure is aimed at providing a framework, rather than mandating a format. The underlying database schema will necessarily need to be rather complex to deal with the multitude of different formats of attack surface model which may be designed.
For each asset or interprocess communication method, source and destinations are defined – this may be a many:many relationship. When these are in different security domains, a primary threat vector may be generated for threat modelling. When these do not cross a domain a secondary threat vector may be generated – for example where defence in depth may be involved.
It is planned that development will begin at the Process and below level, higher levels will not be addressed until later in the development process. (Note: Development has proceeded with this plan. There is support for networks etc but I’ve focused on processes and below, as well as the capabilities an OS may have.)
Example Attack Surface Model
We will now explore an example attack surface model, designed from the top down, using MINERVA as an example. Figure 3 shows the highest level architecture, which is made up of only two parts. Each of these would be stored as a separate process set, on an undefined appliance. By having the appliance undefined, this means that the processes may be on the same, or different, appliances. Each process set is in a different security domain, meaning that the SOAP over HTTPS (Note: JSON over HTTPS is actually being used) crosses between security domains and hence represents a threat.
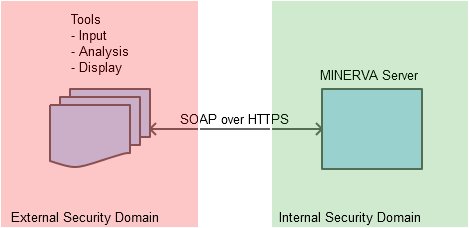
Figure 3: High level DFD
This high level data flow diagram (DFD) provides structure, but isn’t especially useful of itself. The MINERVA server can be further decomposed as in Figure 4. This takes the MINERVA server process, with a single thread, which contains the components described. It should be noted that the Database here is a component, rather than an asset – assets are specific, whereas components are generic.
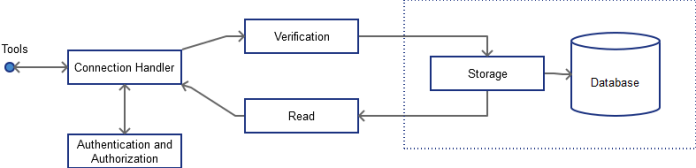
Figure 4: MINERVA Server DFD
The dotted part of the MINERVA Server DFD can be further decomposed, and made more specific, as shown in Figure 5. When decomposition occurs, stubs will be auto-generated based on the higher level, for example in Figure 5 the Verification and Read stubs are present. Normally the components defined in the higher level DFD would be sketched into the decomposed DFD, such that when the finer grained components are defined in the lower-level DFD then a relationship will be assigned between a higher level component, and the lower level subcomponents (which are just stored as components within the database, with a parent/child relationship).
Also of note in Figure 5 is that a package is defined (SQLite 3) which is a reference to a LIB or DLL – this would be stored as an attribute. A file asset is also defined, in a separate security domain.
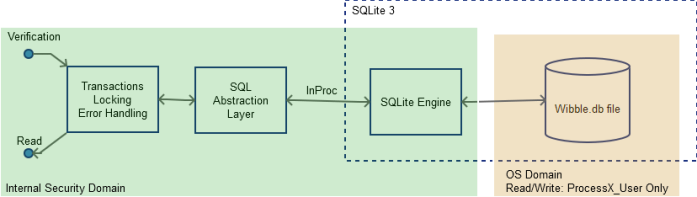
Figure 5: Storage decomposition
Where network components are involved, an alternate type of decomposition may be useful – stack based decomposition. MINERVA knows the network stack involved for an expandable set of well-known protocols, such as SOAP over HTTPS in this case. The user may be prompted with the stack as shown in Figure 6 (Original Version) and the user can then break the stack into relevant components. For example, in Figure 6 (Component Decomposed) the Operating System (defined by the Appliance) handles up-to and including TCP. The process then uses OpenSSL (with a specified version) for parsing of SSL, and the Connection Handler subcomponent is used for HTTP and SOAP parsing. Of course, MINERVA may also make a guess about the stack – for example if it knows HTTPS is in use, and also notes that OpenSSL is an included DLL.
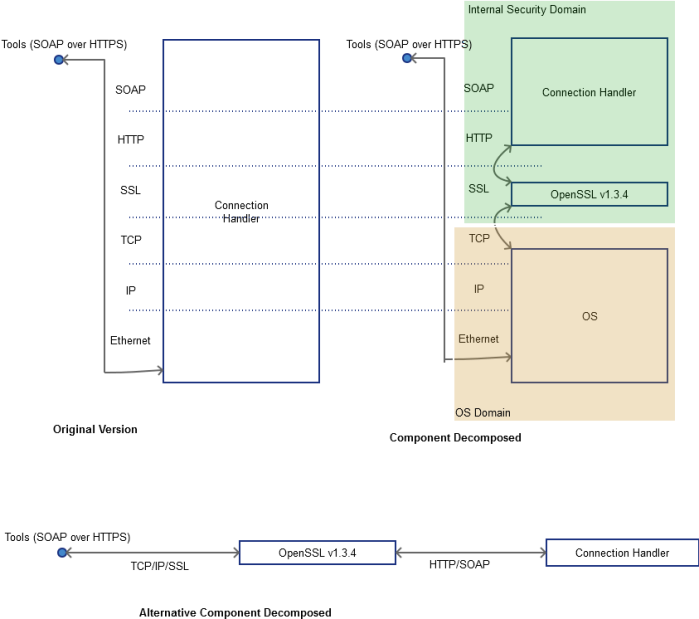
Figure 6: Connection Handler Decomposition
The Connection Handler in the decomposed version is a different Connection Handler to that in the Original Version. The system is aware of this because it has different connections – it communicates with OpenSSL rather than ‘Tools’. The name of a component is stored as metadata, rather than it being the identifier.
An alternate method for decomposing is shown in Figure 6 (Alternative Component Decomposed). This doesn’t use the stack decomposition method, but rather appears more as a protocol break. This display may be more appropriate for display when numerous components are shown rather than just the high level Connection Handler, however it will be less common for attack surface model creation by novices. This is an example of how different types of display may be used for different scenarios.
What can be done with this information
When constructing an attack surface model from the top down, the data collected can be used to verify the low level implementation.
Processes
- What dynamic libraries should be loaded?
- What files should be opened, and in what mode (r/w/x)?
- What network connections should be opened/listened for?
- What IPC methods should be defined, with what permissions?
- What OS privileges/permissions should the process have?
Net
What firewall rules should apply?
Similarly, what Intrusion Detection System rules could apply?
Should the connection be encrypted? This can be tested for.
Should there be authentication? This may be tested for.
File
What files are opened, and how (exclusive access?, r/w/x)
What permissions should any files have (vs the user the process is running as, and vs other users which may need to access the file)
Lib and DLL/SO files
What versions are in use? These could be used for bug tracking.
Import attack surfaces and threat models for these products from other MINERVA servers
For a bottom up attack surface model, all the above may be collected, and used to construct the attack surface model. For example a scan may find that ProcessX.exe has:-
Network: Listening on tcp/8001
File: wibble.db (identified as a SQLite3 Database by tools such as file or TrID)
DLL: OpenSSL version a.b.c, importing functions to do with SSL
LIB: SQLite version d.e.f (learnt from the build environment)
Makeflags: ASLR (-fPIE), -fstack-protector, -FORTIFY_SOURCE, -Wformat, -Wformat-security
RunAs: UserX, who has standard user permissions
The import tool could take this information, and use this to prompt for the following:-
- Net
-
- What protocol is on tcp/8001?
- Where are connections from tcp/8001 expected from? What security domains?
- Files
-
- For wibble.db, confirm that it is a SQLite 3 file
- What assumptions are made about access to the file, which users, apps, etc should have access?
- What data is stored – is it sensitive?
- Should it be encrypted? Should it hold data that is encrypted by the app?
This can all be used to define an attack surface model, with minimal overhead.
Once an attack surface model has been defined, this could also be used to perform “what if” analyses. For example, what if component X was compromised, and hence the security domain it is in changes?
Something that may also be attempted would be to take an attack surface model for a product for a given OS, and change the OS. Different operating systems have different privileges, capabilities, and permissions, and MINERVA could help prompt for and define those which should be used for new and different operating systems.
Design Decisions
The MINERVA server will be written in C#, due to familiarity with the language, cross platform support, and extensive tooling already existing for it. Tools will be written in whichever languages make sense. C# will be the default choice with native extensions where needed, however the Linux application will likely be Perl due to ease of programming.
The network protocol used will be HTTPS, as it is a standard and will support all necessary requirements. SOAP may be used over this, again for standards requirements. REST was considered, however the authentication requirements and large payloads mean that SOAP will be the most suitable. This decision may be revisited when development is under way. (Note: Currently using JSON, as it’s vastly easier to code for).
Authentication will initially be against credentials held in the database, as this will be the easiest mechanism to implement and non-enterprise customers may prefer it. HTTP(S) authentication, against OS/AD credentials, is a stated aim for the future, to facilitate enterprise use.
The database will be SQLite initially due to ease of use. There are scalability concerns with SQLite however, which may require support of an enterprise grade database in the future. All database operations must therefore go through an abstraction layer in order to ensure that any future changes are as painless as possible. (Note: Doing code-first database development, it was easiest to use MS SQL.)
The main OS to be targeted for development will be Windows 7 and later, although where possible the design and implementation should be host OS agnostic. v1.0 should also include support from Linux clients/targets, and possibly also Android.
Minimum Features
As seen in the high-level design, the majority of the functionality of the solution depends on external tools. The following tools and features are the minimum desired set which must be in place before it can be deemed to be version 1.0.
Graphical UI for creation of attack surface models diagrammatically
People are used to drawing attack surfaces, and for simple systems this may still be the easiest way for knowledgeable users to create high level threat models. The Microsoft TM tool has become the de-facto standard for this, and so a similar tool will be needed for MINERVA. This tool would allow the graphical representation, as a data-flow-diagram of attack surface models, for viewing, creation, and modification of attack surfaces at all levels. (Note: Currently just using exports from the MS tool, but there are serious problems when deeper integration is desired. For example, having the ability to right-click on a graphical node, and then automatically scan the associated process/file).
UI for creation of attack surface models textually
For larger and more complex attack surfaces, creating attack surface models diagrammatically isn’t necessarily ideal. Furthermore, while a drawing canvas is good for people versed in the creation of these diagrams, for non-security-specialists a text-based input method may be best. This would allow users to list, for example, all the different interfaces, IPC, etc used, and then describe how these are implemented by different components. This would also allow a tool to prompt the user for more information, and make them think in a certain way. (Note: Currently implemented in a datagrid)
Windows Process Scanner
One way to identify an attack surface is to scan a running system. This can work in several ways: by analysing a system before and after an application is installed and then comparing these, or by monitoring a processes execution to detect files, IPC, network connections and the like that are created dynamically. Realistically both will need to be used.
The Microsoft Attack Surface Analyzer performs the former task already – the MINERVA tool will allow the import and parsing of these. There are a number of different tools which provide the latter functionality, however it is most likely that something custom will be written, albeit using commonly known and used techniques to gain the desired information. (Note: Currently using text output from Sysinternals Process Explorer etc – although the plan is to write a more tightly-coupled tool in the future)
Linux Process Scanner
This would be the Linux equivalent to the Windows Process Scanner. For version 1.0 it will only include support for a couple of the more common distributions.
Stupid Source Scanner
Some components, such as static libraries, cannot be scanned using the previous tools. Therefore a basic tool will need to be written to grep through source code and development environments to try to generate an attack surface. There already exist tools which spider source code, looking for security issues for example, however few of these allow third party plugins or extensions.
While the preferred solution for this tool will be to extend an existing third party tool, a custom tool may need to be written. The tool would need to be able to handle the following for version 1.0: parsing of Makefiles, MS .VSProj, C/C++, C#, and Java. For version 1.0 the quality of the parsing/spidering will be very basic – essentially grepping for specific APIs, and identifying linked libraries.
Use may also be made of code annotations for the likes of Lint, and C# Contracts. It should be noted that the aim of the Stupid Source Scanner is not, certainly initially, to be anything like complete, rather it is to get quick and dirty information out of the codebase with minimum involvement of developers.
Microsoft Threat Model (.tm4) Import Tool
The Microsoft TM tool is the standard for creation of attack surface diagrams, and using this to create threat models. These are saved in .tm4 files, which are simple XML. As a lot of security-aware enterprises may have already attempted to create threat models using this tool, for a subset of their components, it is vital to be able to import these into MINERVA. For version 1.0, attack surfaces must be imported, however the threat models themselves do not need to be parsed – they can just be stored until support is added with a later version of MINERVA.
Support for exporting as a .tm4 may also be added, depending on ease.
Administration Tool
Any product whose aim is to hold security-sensitive information, and be used by large numbers of users, must support authentication and authorization checks. These in turn require administration. Likewise and administrator must be able to decide which attack surface models, for which components, and to what level of detail, may be shared externally. The administration tool will provide a mechanism to perform these administrative functions, as well as access to logging including security audit logs.
Inter-Service Interface
A stated aim of MINERVA is to allow sharing of attack surface models between different instances of MINERVA. Rather than building support for this into the MINERVA server itself, a separate tool is desirable for security reasons as well as to simplify implementation. The ISI will essentially just be another tool, running with its own credentials, and so even if the ISI were to be compromised then that wouldn’t lead to compromise of the server itself.
Threat Model Generation
An obvious use for an attack surface is to automate generation of threat models. This tool will perform this generation, and could potentially allow user interaction with the threat models themselves – although this could be implemented as a separate tool.
Test Plan and Coverage Generation
Once an attack surface has been designed, test plans and coverage analysis may be an alternate way to convey to developers the same information as a threat model would. This tool could list, for example, the different tests which should be performed to gain assurance that the implementation is secure – for example it may call out the network interfaces to fuzz, the files to try modifying, and the like. By conveying the information in a way that developers are more used to understanding, this may help increase coverage of security-relevant testing – for example many developers do very little ‘negative’ testing, and instead rely on ‘positive’ testing.
Firewall Exception Generation
Through analysis of network connections/interfaces, a list of expected firewall rules together with protocols may be generated. This would be of use to customers, where a developer has used MINERVA, for example to know what firewall exceptions to put in together with what network traffic their Network-IDS should be detecting. It will also be useful for developers to detect and enumerate unexpected network connections, for example debug support which have accidentally be left in.
Development Order
A proposed order for the development of the minimum features is below. For each feature, support will be added to the main server as needed. The first step will of course be to create the server itself, with backing database and network APIs. Following this, a rough administration tool will be written – this will allow testing of the network APIs. The UI tool for textual creation/representation of models will be next, due to ease of implementation, and to allow further testing of the server, and then threat model import in order to be able to quickly fill in examples. The Stupid Source Scanner, and either the Windows or Linux Process Scanner will be next, to test bottom-up attack surface construction. At this point the solution will in some ways be surpassing what is currently available in the public domain.
The Inter-Service Interface will next be stood up, to test being able to import/export between MINERVA instances. Writing a Graphical UI for attack surface diagrams will likely be non-trivial, and so until this point the MS TM tool will have been used extensively. However, this is a necessary tool to have, and so it would be written at this point. This is the last tool to input attack surfaces. The generation and analysis tools will finally be written, as these are dependent on a number of previous features.
So, in summary, the rough order for development will be as follows, although of course there will likely be overlap between all of these.
- MINERVA server
- Administration Tool
- UI for creation of attack surface models textually
- Microsoft Threat Model (.tm4) Import Tool
- Stupid Source Scanner (Note: I’m doing a v0.1 of the Windows Process Scanner first)
- Windows Process Scanner (Note: v0.1 takes the text output from existing tools such as Sysinternals Process Explorer)
- Inter-Service Interface
- Graphical UI for creation of attack surface models diagrammatically
- Linux Process Scanner
- Test Plan and Coverage Generation
- Firewall Exception Generation
- Threat Model Generation
Stretch Goals
While the above are the minimum features, there are several other tools and ideas that may prove desirable at some point.
Binary Analysis
Parsing of DLL/SO or LIB files to look for interfaces, for example looking at import tables to identify APIs in use.
Common Criteria Security Target Generation
Common Criteria relies on a Security Target document, which states how a product meets certain design requirements. This document is very onerous to create, but there are some aspects which could be automated based on attack surface diagrams and mitigations called out in threat models.
Graphical UI for other diagram types
The standard diagram type for attack surface diagrams is the dataflow diagram. However, other diagrams may be useful at times, for example UML Class, Package, and Activity diagrams may all be useful at certain levels of attack surface model.
Taint Tracking
If there could be some standardisation of attack surface model components, plus the expected contents of files, IPC, and network traffic, then some form of taint tracking may be possible. For example, if a file should be encrypted, and a high-level component is flagged as performing encryption, then the low level analysis could perform source code or dynamic analysis to identify whether encryption APIs are in fact being used. If there was no high-level component which was flagged as performing encryption, then that could be identified as an issue.
Current Status
Since submitting to Cyber10k, I have begun actual development of MINERVA – as noted before, winning Cyber10k would be a bonus but I was planning to give it a stab anyway. Of course, finding out I won has added a certain impetus.
The Minerva server is currently operational, albeit with no concept of user controls (for administration), or data versioning. Nonetheless, attack surface models can be stored and queried, and the combination of separate threat models has been proven – for example when two ‘solutions’ read/write from the same file, or listen/connect to a network connection, then correlation can be performed and arbitrary attack surface models drawn which may include some of each solution.
I used code-first database design techniques with Visual Studio, in C#, and so have used MS SQL, with JSON as a protocol just because it’s so damned easy. I have an administration client which also allows me to manually add/delete/modify attack surface models via a table-like UI. I can import MS .tm4 files, but this hasn’t been tested with the newest generation of the Microsoft Threat Modelling tool. Export to .TM4 isn’t yet supported either. I’m currently working on using the text/CSV output from existing tools such as dumpbin, and Process Explorer, as a temporary stopgap for proof-of-concept of the Windows Process Scanner. The next steps will be to export threat models, perform a few bits of analysis, and then have a custom-written Windows Process Scanner.
Fingers crossed, I’m hoping to be alpha-testing in November, with a v1.0 by March 2015 (by which point I may need to get a real job again :( ). Still, things are looking remarkably good at the moment.
Anyway, I hope this was of some interest to some people. Please feel free to hit me up if you’re interested in alpha- or beta-testing Minerva, or have any other queries – always happy to chat. In addition to the blog, feel free to email me at minerva at ianpeters.net.
/cdn0.vox-cdn.com/uploads/chorus_asset/file/3327290/hololens.0.gif)










{kind=link}